
PS: The thesis has been published from Lincom-Europa, München, Germany in 2006. Please contact the PUBLISHER for further detail.
GRAMMATICAL AGREEMENT IN HINDI-URDU AND ITS MAJOR VARIETIES
Pradeep Kumar Das
PhD submitted to Centre of Linguistics and English, JNU, New Delhi-67, India.
Thesis supervisor: Prof. Anvita Abbi. Degree awarded in 2005.
ABSTRACT
The notion of “Grammatical Agreement”, which functions like a bridge between the boundaries of ‘morphology and syntax’, is one of the interesting aspects of synchronic study of languages. ‘Grammatical agreement’ mainly explains those phenomena that exhibit the property of specific morphological form of a word appearing in a sentence with respect to the presence or absence of some other words elsewhere in the sentence. This is probably why Lehmann (1988:55) prefers to call ‘agreement’ to be referential in nature. It is referential because it helps to retrieve the referent(s). Agreement does this by encoding the information on grammatical properties of its referent(s) (i.e. the NPs) into the morpheme(s) that appear(s) with the verb in the sentence. In other words, it deals with the distribution of an inflected word (i.e. the verb) with respect to the properties of other words (i.e. the PNG[1] of the Sub & Obj NPs) in the sentence. It is for this reason, ‘grammatical agreement’ is said to be closely related to the ‘inflectional morphology’ in nature, as it also looks into the effect of ‘grammatical morphemes’ on word structure i.e. the morphemes that carry information about tense, aspect, person etc. in the sentence. Grammatical agreement helps us to explore and explicate how languages are structured. There are a number of definitions that have been put forward to account for the phenomenon. A commonly accepted definition of ‘grammatical agreement’ in the literature can be summed up (adopted from Lehmann (1988: 57) with some modifications) as:
Definition of ‘Grammatical Agreement’:
We could interpret the above definition in the following way, the verb (i.e. Y) agrees with an NP (i.e. X) in a category Z (i.e. the bound morpheme(s)[2]). The first condition laid out in the definition is very clear. There exists a syntactic relationship between the verb and the NPs in the sentence. We will have to assume that there is an underlying relationship between the O-features (i.e. the PNG represented as is ‘z’ here) and the noun phrase in the sentence and this relationship is independent of the nature or kind of the verb. The ‘z’ (the nominal inflection) is a subcategory of the grammatical category ‘Z’ (the verbal inflection) and this part of the condition is also understandable. The last condition suggests about the formation of a constituent (i.e. the VP) and this happens when the bound form(s) or the null marker of agreement feature appear(s) with the verb in the sentence. A few examples of the aforementioned definition and its explanation that is presented will help to see through the complex features and their function for agreement:
1.

2.
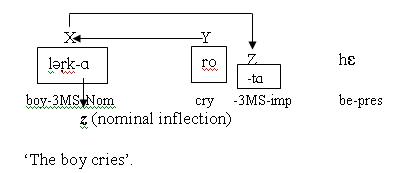
2a.

In the above examples (1-a), the verb agrees with the subject in ‘number and person’ in English because there is a grammatical relationship between the number and person specifications of the subject NP and the suffixes across the subject of those sentences that are in the present tense. In this grammatical configuration, if the subject NP is a third person singular nominal, the suffix ‘-s’ becomes the agreeing category for the constituents ‘X &Y’ and if it is in some other number and person, the suffix is ‘-O’ (zero).
The examples (2-a) from Hindi-Urdu make the conditions of the definition for agreement more clear. The first condition is explained by the arrow which is drawn from ‘Y’ to ‘X’ and this tells us that there is a syntactic relationship between the verb and the subject in the clause. The nominal elements in these examples have their own inflection categories which we have called ‘z’, a subcategory of the grammatical category ‘Z’ i.e. the verbal inflection. The second part of the condition (b) i.e. ‘….and X’s relationship to z is independent of the nature or value of Y ’, can be understood if we compare the nominal inflections that occur in examples (2&2a). The O-feature of the nominal, ‘-A’, ‘3MS’of (2) changes to ‘-e’, ‘3MPl’ in the example (2a). This substitution of the nominal inflection is due to the desire of the speaker to change the number category of the nominal. This change in the form of nominal elements is independent of the nature and value of ‘Y’ i.e. a verb. The next condition is explained by pointing out the similarity between the nominal and verbal O-features in the examples. The last condition tells about the way the verb and the verbal inflection (which is a co-indexed property of the nominal inflections) combine and form the verb phrase. There is no problem in following the condition.
This thesis has explored the issue of ‘Grammatical Agreement’ from a variety of directions and approaches, focusing on the central question of how the agreement phenomenon works in typologically similar and genetically related varieties viz. Bundeli, Garhwali, Marwari, Bhojpuri, Maithili, Angika, Chhattisgarhi, and Avadhi of Hindi-Urdu. The work begins by defining the basic patterns of grammatical agreement in Hindi-Urdu. Once a layout of the basic patterns has been worked out, we have tried to test the agreement patterns on the major varieties of Hindi-Urdu.
In order to do this, we have divided the thesis in four chapters. The first chapter presents the theoretical overview of agreement phenomenon and a review of different approaches and treatments to the phenomenon. The chapter also highlights the shortcomings of each of these proposals by presenting the evidence from Hindi-Urdu which remains unexplained by the rules posited by the researchers. What emerges from the review of these attempts to explain the agreement fact is that researchers in the area can be classified into two distinct groups. The researchers in the first group like Allen (1951), Kachru et al. (1976), Saksena (1981 & 1985), Khan (1989) and some others have treated the issue of agreement a very simple phenomenon. They have, thus, prescribed some rules for agreement which, of course, take care of the attempted set of examples, however, these rules leave out the whole set of complex predicates and their agreement patterns unexplained. The other group of researchers like Gair & Wali (1989), Mahajan (1989) and some others have mixed up the issue of agreement with other linguistic issues and given a secondary treatment to the agreement phenomenon. As a result, the agreement rules proposed by the above-mentioned researchers are either dissatisfactory or become very complex to follow their line of argumentations. This also makes these rules difficult to be applicable for other languages without a fair amount of explanation of the framework, which seems to divert the whole attention from issue[3].
The second chapter provides a detailed analysis of agreement patterns in Hindi-Urdu. In order to overcome the ongoing problems (i.e. from Allen’s work of 1951 to till date) in the area of agreement, we have divided the second chapter in various subsections. The purpose of these subsections is to investigate the nature of agreement pattern in different types of clauses. We felt the need during our coalition and analysis of the data in Hindi-Urdu that it would not be possible to examine the nature of different types of clauses and their agreement patterns if we were guided by the general rule of agreement[4] prescribed for Hindi-Urdu in the literature.
Therefore, we decided to divide the chapter primarily in two sections where we first examined the agreement phenomenon in simple clause and then we looked at the issue in complex clause in the next section. We have examined the behavior of the case-markers and their roles in the agreement morphology in Hindi-Urdu. This has helped us to formulate different sets of agreement-rules for different types of clauses. The core assumption of these rules, however, remains the same as laid out by the researchers in the literature.
The classification of the data in different types of clauses also helped us to keep one set of rules for one type of clause and other set of rules for a different type of clauses. We have shown that the simple rule of agreement i.e. the verb in Hindi-Urdu agrees with the leftmost unmarked nominals, which has been mentioned in many research works, operates fine on the so-called simple clauses. The rule, however, does not seem to account for the agreement patterns of complex predicate without an explicit explanation of various structural features of these complex predicates.
Looking from the standard view of tense-aspect conditioned ergativity, scholars have maintained that a transitive verb in Hindi-Urdu does not show agreement with the subject in perfective aspect. The claim, though, has been refuted in the second chapter where we have shown that there are instances of subject-verb agreement possible in perfective aspect in both transitive and ditransitive clause. We have presented the function of so-called ‘indecent auxiliaries’ such as ‘c&UkA’, ‘finished’ and ‘g«yA’ ‘gone’ which are used as the helping verb of the clause and they covert any ‘ergative’ sentence into its ‘no-ergative’ counterpart. They also facilitate subject-verb agreement in the later constructions. Therefore, we have proposed for a rectification in the definition of the subject-verb agreement. We also need to make the conditions more powerful that define the occurrence of an ergative case marker in Hindi-Urdu, so that, there are no exceptions of the rules[5].
The next issue that we have taken in detail is the compound verb constructions. We have examined the case of compound verb constructions with all four permutations and combination of V1+V2 with the ± transitivity of the verbs. This has helped us in finding the nature of the vector or explicator verb (i.e. V2 in the series) and we have proven with the help of the examples that the ± transitivity of the whole constituent (the compound verb series) actually depends on the ± transitivity of the vector verb. The major test for the hypothesis that we have used in such instances to prove the point is the possibility and impossibility of an ergative marker ‘-ne’ in the sentences with these complex predicates. We do not find this point being mentioned in any work on the compound verb constructions in the literature.
The conjunct verb construction is another kind of complex predicates that has been problematic with regard to the agreement patterns in such constructions. We have drawn upon the hypothesis outlined in Mohanan (1994) and described the phenomenon in detail. We have explained the phenomenon with the help of thematic role of the arguments of the clause and the sub-categorizations of both the ‘complex predicate’ and the ‘simple predicate’. We have tried to account for the extra nominal with these mechanisms. We have also shown how the postpositions of different kinds which occur with the argument that precede the so called ‘host’ of the complex predicate decides whether the nominal ‘host’ will be one of the arguments of the clause or it will be an internal part of the complex predicate. This is, of course, a mere explanation of the phenomenon than a solution of the problem of ‘conjunct verb constructions’, but this helps us to formulate the generalization of the agreement patterns in such constructions.
The chapter then deals with the issue of infinitives and agreement in detail. There are at least two well-established treatments to the infinitives in Hindi-Urdu. For some scholars, infinitives are verbal in nature while for others, it should be nominals. We have first presented these arguments in detail then explained as to why some instances of infinitives must be treated as verbal elements as they are modified by an adverbial element than the adjectival modifier. The same treatment can to be extended for other occurrences of infinitives where the whole infinitival constituent can bear various kinds of case suffixes. The case suffixes can only occur with the nominal element. This helps us to claim that those instances of infinitivals that bear the case suffixes must be analyzed as the nominals. Nevertheless, there is a third treatment to the use of infinitivals in Hindi-Urdu. Mohanan (1994) argues for the case of incorporation. We have mentioned Mohanan’s point of view, however, we have expressed our reservations for the acceptance of such explanation.
We have then examined and presented a tangible solution to the problem of agreement pattern in so-called ‘small clause construction in Hindi-Urdu’ in the chapter. We have again explained the phenomenon of small clause with the help of thematic role of various arguments in the clause and the sub-categorization of the verbs that are used in the so-called small clause constructions. The argument-like elements in such constructions are in fact modifiers of the noun phrases. We have taken the help of Jackendoff’s (1990) distributions of primary and secondary predications to prove the point that the argument-like elements are not actually arguments but they are the modifiers of nominals of the clause. With these findings and explanations, we have classified some of the varieties of Hindi-Urdu in so-called ‘dual system of agreement’. The classification is based on the correlation of CASE suffixes and agreement morphology that function in different ways in different context.
The third chapter is a justification of our classification and it supports our explanation of various kinds of agreement patterns discussed in the second chapter. The application of the rules, formed in the second chapter, to the selected varieties of Hindi-Urdu in the third chapter confirms our explanation of the phenomenon. In this chapter, we have argued for a ‘dual-system’ of agreement. This dual system of agreement highlights the interaction between the case-suffixes and the agreement phenomenon. In other words, the presence or absence case-suffixes with the nominals and that of the agreement morphology with the verb stems establish and define the role and function of the case suffixes and the agreement morphology. We have shown on the basis of the observation of the function of agreement morphology that a language which is classified as having a dual-system of agreement, the subject-verb agreement and the object-verb agreement alternates in the language due the certain syntactic environment brought about by the case makers. So, the distribution of subject-verb and object-verb agreement seems to be in the complimentary distribution. This is why we have called such a system as the dual-system of agreement. The agreement morphology and the function of case suffixes in the varieties classified as having such a system prove the point in the chapter.
The fourth chapter deals with some of those varieties of Hindi-Urdu, which show a single-system of agreement. We have defined the ‘single-system of agreement’ in following way: a language should be classified as having a single-system of agreement if the subject-verb agreement and object-verb agreement do not alternate. In other words, there is no separate system of object-verb agreement in such languages. This definition does not exclude the possibility of object-verb agreement in the language. The definition, however, certainly denies the existence of a separate system of object-verb agreement in a sense that it is mutually exclusive or in complementary distribution with subject-verb agreement. It is for this reason that we have given a term such as ‘the simultaneity of subject and object verb agreement’ in case the language shows any referentiality of the object NP(s) on the verb. Since the subject NP necessarily triggers agreement on the verb and the reference of object NP on the verb seems to reflect the ‘pragmatics of the language in question’, we have called such a system of agreement a ‘single-system of agreement’.
It is obvious that these two systems of agreement present a contrast in the syntactic environment for the mediation of agreement phenomenon. For example, if the postpositions function as the blocking element or a constraint for the agreement between the verb and the nominal in the languages having a dual-system of agreement, these postpositions have no such function in the languages that have a single-system of agreement. The postpositions play a crucial role in the change of the thematic role of the arguments in the languages that have a dual-system of agreement. We came across such function of the postpositions in such languages when we dealt with the issue of ‘conjunct verb construction’. Such role of postpositions was absent in the languages that have a single-system of agreement. Thus, we could conclude by saying that the classification of the above-mentioned varieties of Hindi-Urdu in these two broad groups has helped us to overcome the problems in the area of agreement phenomenon. If we accept these classifications and value their typological application, the problems that we have highlighted in the proposals of the other researchers in the areas seem to find a logical solution. We, however, would like to appeal the future researchers in the area to test the proposed classification on other group of languages from different language families and see if the hypothesis also works in other languages. This empirical testing of the hypothesis will add a new facet in the research of agreement phenomenon and will change the world-view of the researchers in the area.
References:
Allen, W.S.(1951) A study in the analysis of Hindi Sentence-Structure. Acta linguistica Hafniensia 6: 68-86.
Gair J.W. and K. Wali (1989) Hindi Agreement as Anaphora. Linguistics 27: 45-70.
Jackendoff, R. (1990) Semantic Structure. Cambridge, The Massachusetts Institute of Technology Press.
Kachru, Y. et al.(1976) The Notion of ‘Subject’; A note on Hindi-Urdu, Kashmiri and Punjabi. In M.K. Verma (ed.), The notion of Subject in South Asian Languages. Madison, University of Wisconsin.
Khan, B. (1989) A note on disagreement in Hindi-Urdu. Linguistics 27: 71-97.
Lehmann, C. (1988) On the Function of Agreement. In M. Barlow & C. A. Ferguson (eds.), Agreement in Natural Languages: Approaches, Theories & Descriptions. Stanford, Centre for the Study of Language and Information Publication.
Mahajan, A. (1989) Agreement and Agreement Phrase. The Massachusetts Institute of Technology working papers in linguistics 10: 217-252.
Mohanan, T.(1994) Argument Structure in Hindi. Stanford, The Stanford University Press.
Saksena A. (1981) Verb Agreement in Hindi. Linguistics 14: 467-474.
Saksena A. (1985) Verb Agreement in Hindi Part-II: a Critique of Comrie’s Analysis. Linguistics 23: 137-142.
Saleemi, A.P. (1994) ‘If That’s Case, I don’t Agree’: Case, Agreement and Phrase Structure in Hindi-Urdu. Paper presented at the South Asian Linguistic Analysis Roundtable XV, Iowa City, The centre for International and Comparative Studies, University of Iowa.
[1] PNG is a commonly accepted abbreviated form that refers to Person, Number & Gender. It is also known as O-features (or phi features). For example, ‘the boy’ will get the PNG value as 3MS (i.e. 3Person Masculine and Singular).
[2] Bound morpheme in case of languages other than Isolating type of languages. Morpheme could be more than one in case of languages where the ‘agreement markers’ are more than one and they show agreement with SUB and OBJ both. Maithili is one example in the present work that requires more than one bound morphemes to encode the agreement with SUB and OBJ.
[3] See Singh (1993), Butt (1995), Bhatt (1993) for a more detail criticism of such proposals.
[4] The rule reads like ‘…the left most unmarked nominal triggers agreement on the verb’.
[5] We have argued to highlight the perfectivity of the MAIN VERB as one of the conditions for the occurrence of the ergative case marker. It has also been supported by Saleemi (1994).
©
Pradeep Kumar Das
University of Delhi
Delhi-110007